
CDAP provides a number of ways to process data in a pipeline, and one of the most flexible ways to build advanced data processing logic is through the use of directives with JEXL expressions in Wrangler. Transformation logic can be created in CDAP studio directly where a number of CDAP plugins are used to source, transform, and sink data by building a directed acyclic graph (DAG) of processing logic, and each of the transformations is done in sequential phases via purpose built transform plugins.
Wrangler is itself a transform plugin, but you can think of it as the Swiss Army Knife of plugins in CDAP, as it acts more like a plugin of plugins. Wrangler has the ability to not only use the default directives that come with CDAP, but you can also include your own User Defined Directives (UDDs) to add custom processing logic.
In this article I’ll show you how to use some of the more advanced features of directives to harness the power of Wrangler to perform transformations with fewer directives. Three of the most powerful and utilitarian of these directives are: set-column, filter-rows-on, and sent-to-error.
# JEXL
Previously I mentioned an obscure acronym. So, what is JEXL you ask? The Apache JEXL page defines it as follows:
“JEXL is a library intended to facilitate the implementation of dynamic and scripting features in applications and frameworks written in Java.”
In other words, it’s a way of scripting Java without actually writing Java code. Bear in mind that this is not a tutorial on JEXL, so it’s definitely worth reading up a bit more on JEXL itself to familiarize yourself with its capabilities. We’ll simply focus on how we can use some of the JEXL goodness to leverage the expressions in our directives to do some interesting things.
Let’s see what Wrangler directives look like with JEXL.
set-column :movie_source “imdb”.toUpperCase()
So what does this directive do? To better understand how these directives use expressions let’s unpack the directive syntax fist.
The syntax for this transform is broken down as follows:
The set-column directive can create a new column in a dataset, or set the column value to the result of an expression execution. It takes a column name as the first parameter and an expression as the second parameter. In this example we are creating a new column named movie_source, and then setting a value for each row in that column to the string “imdb.” The expression can take data as input from a column or it can be set statically. Where JEXL comes into the picture is in the use of the Java String function toUpperCase(). By adding the function in the expression we are instructing the directive to apply the uppercase function from the Java String library to every row where the string is encountered. In this case we implicitly set the string to a static value of imdb, but we could have just as easily uppercased any column value from the dataset.
For example, the following directive would create a new column, movie_source, with all the values retrieved from the source_of_data column, and strings within that column would all be converted to uppercase:
set-column :movie_source source_of_data.toUpperCase()
# Examples
Perhaps it’s a bit early to grasp the power of expressions at this stage, so let’s use a few more examples to illustrate.
filter-rows-on condition-true country !~ ‘US’
filter-rows-on condition-true (country !~ ‘US’ && hourly_wage > 12)
send-to-error Name == null
send-to-error Age.isEmpty()
send-to-error Age < 1 || Age > 130
send-to-error !date:isDate(DOB)
As you can see in the example directives, you can perform calculations within expressions, as well as create variables, assign values, perform logic operations, use Date, Math, and String functions from Java, and the list goes on.
# Emulated Join
One of the benefits of being able to use conditional operators within a directive is that you can emulate a dimensional table for joining data. To illustrate I will use a small movie dataset with MPAA ratings for movies and emulate a dimension table in the directive. For all intents and purposes this will be an in-memory table that will be able to perform super fast joins. Of course this technique is not meant to replace more scalable and maintainable alternatives but for smallish dimension tables, like MPAA ratings with descriptions, or state names with their abbreviations would be a good use case.
The sample data will contain the movies with their assigned MPAA rating abbreviation. Our directive will contain the description of the rating. We’ll check the sample dataset for the column with the MPAA rating and create a new column that provides the description for the rating as well.
The CSV file containing the sample data used in this article can be found here.
In CSV format our dimension table would look something like this:
G, General audiences — All ages admitted
PG, Parental guidance suggested — Some material may not be suitable for children.
PG-13, Parents strongly cautioned — Some material may be inappropriate for children under 13.
R, Restricted — Under 17 requires accompanying parent or adult guardian.
NC-17, No one 17 and under admitted.
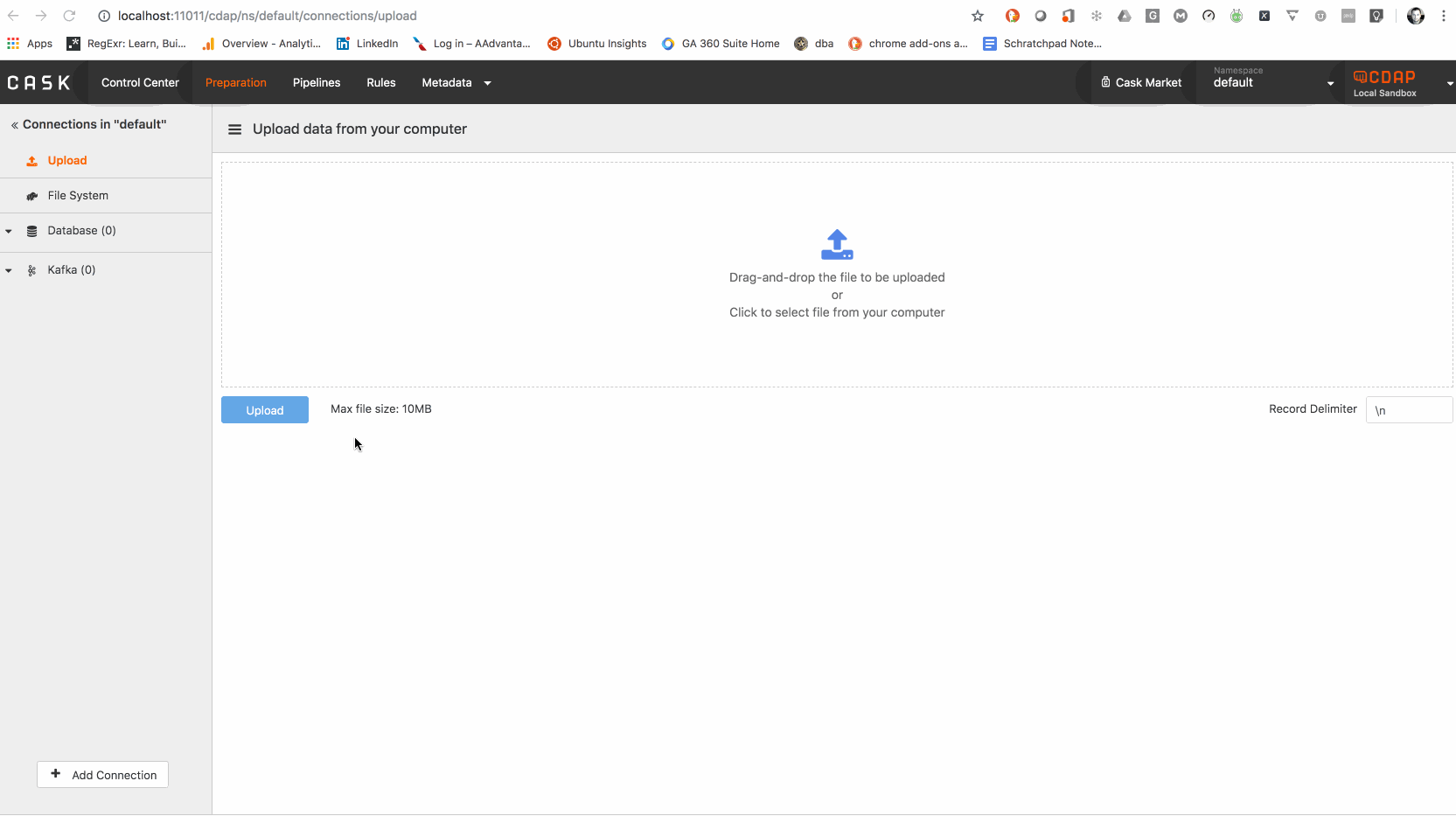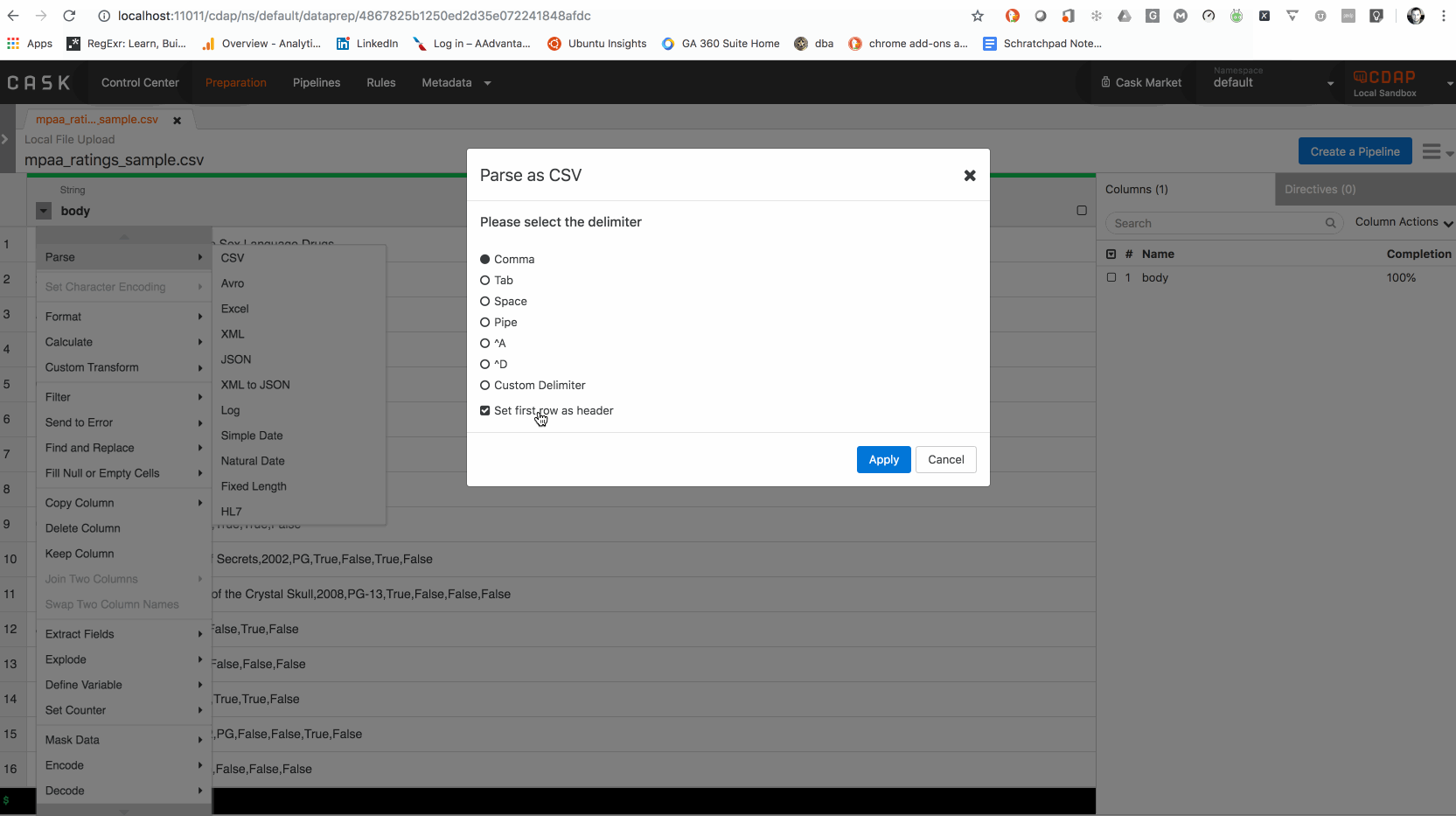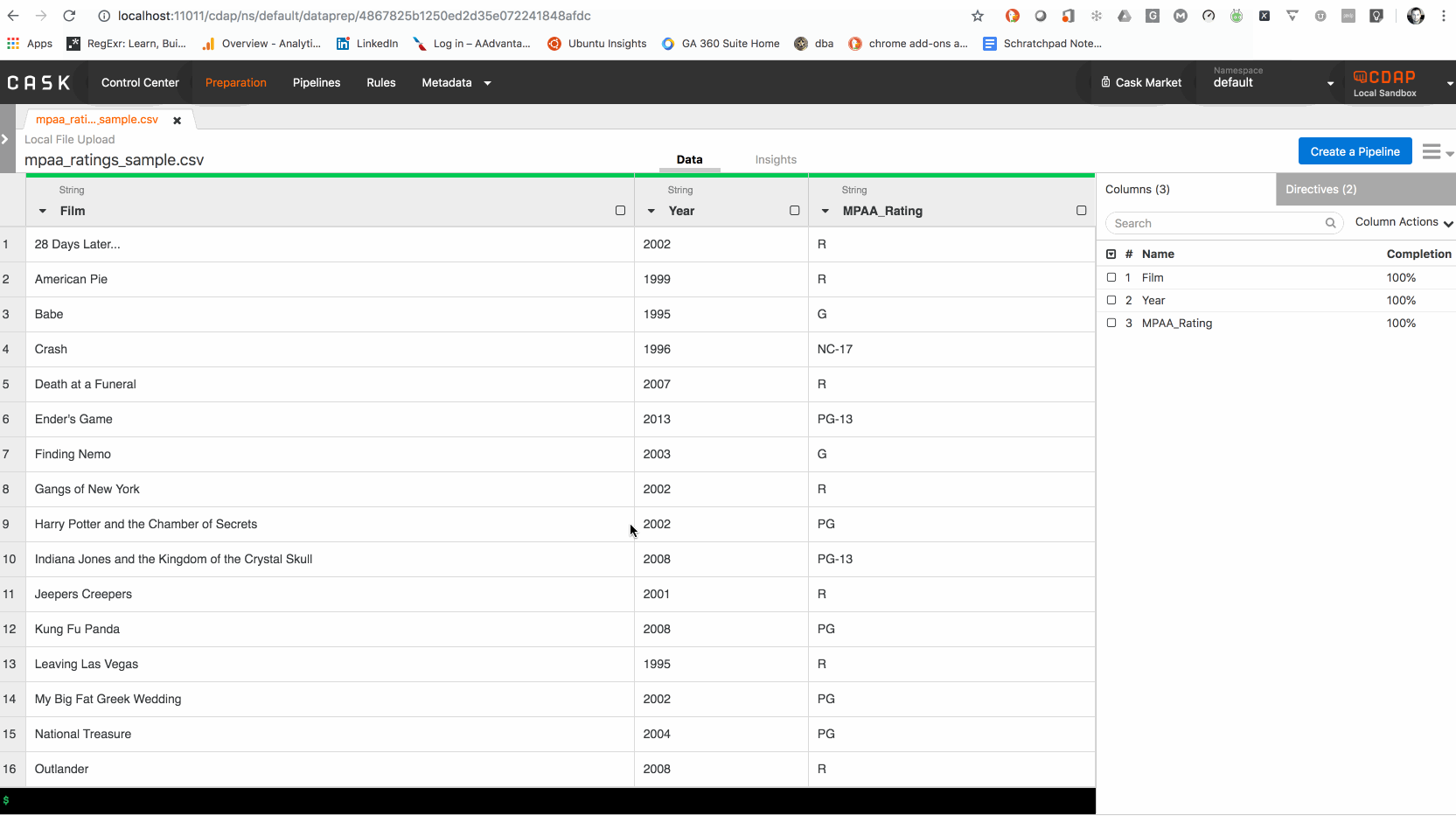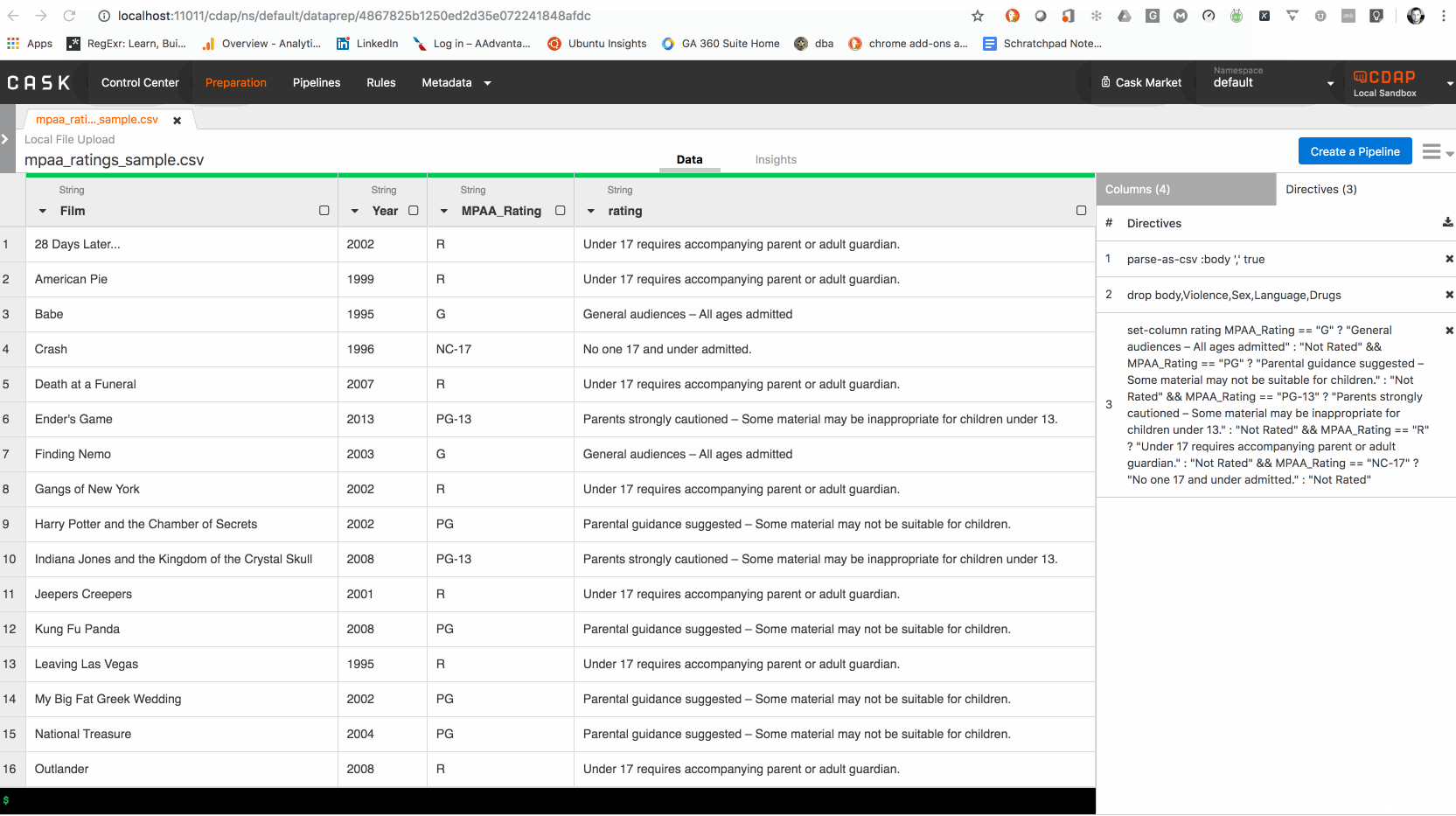
We turn that data into a directive:
set-column rating MPAA_Rating == “G” ? “General audiences — All ages admitted” : “Not Rated” && MPAA_Rating == “PG” ? “Parental guidance suggested — Some material may not be suitable for children.” : “Not Rated” && MPAA_Rating == “PG-13” ? “Parents strongly cautioned — Some material may be inappropriate for children under 13.” : “Not Rated” && MPAA_Rating == “R” ? “Under 17 requires accompanying parent or adult guardian.” : “Not Rated” && MPAA_Rating == “NC-17” ? “No one 17 and under admitted.” : “Not Rated”
As you can see this directive uses the ternary conditional operator and performs 5 evaluations. Because these evaluations take place in a single directive they perform much faster than if separate directive would be called five times per record in the dataset.
# Conclusion
Directives are used to transform data within the data preparation UI — Wrangler — which provides immediate feedback to the user as the transformations are applied. Once a pipeline is published the transformations run in parallel across any number of nodes in a cluster. What makes Wrangler even more powerful is that you can chain Wrangler plugins together to create units of transformation, so the output of one Wrangler step becomes the input of another Wrangler step in a data pipeline.
By leveraging the power of the expressions in directives you can come up with creative ways of solving data engineering problems.